




How to use AI safely
What are the main problems of AI’s regarding security? And how can you protect your organization against these risks?
> Your Challenges > How to use AI safely?
Using AI Safely
Author: Ralph Moonen, Technical Director at Secura/Bureau Veritas
With the enormous growth in capabilities of AI’s, and in particular Large Language Models (LLM’s), our customers are increasingly asking for guidance on the security of AI’s. Is it possible to use AI safely? What are the main problems of AI’s regarding security? And how can you protect your organization against these risks?
I think most people will agree that the level of usefulness of AI’s and in particular LLM’s has gotten to the point that you can no longer ignore them. In business, they can be great production boosters for text-related tasks such as translations or summaries.
For software development AI’s can also provide excellent coding and debugging assistance. For instance, you might want to ask ChatGPT or Claude 3 to generate code or help debug. It is enjoyable to become creative and if you want to see what’s possible, then the thread at https://twitter.com/javilopen/status/1719363262179938401 is an amazing example. Another way to use AI’s in coding is for assisting in reverse engineering, decompilation and other tasks. This can be powerful when trying to figure out functionality of certain code.
Hallucination and copyright issues
Of course, AI’s tend to hallucinate: check and validate all output or you might be trying to use code constructs or command line parameters that have no basis in reality. Also: output from public and generative AI’s has no copyright: you can use it as you see fit (including images, texts, source code and software). But you can also not claim your own copyright, so selling it or using it in products might be problematic. These are general risks you face when using AI.
The two main security risks of AI
There are also more specific security risks associated with the use of AI’s.
Risk 1: Leaking information
The first security risk when using AI's is that everything you upload or copy or paste into an AI essentially means you are leaking that info. Regardless of features or switches or configurations of the AI model, if you upload sensitive information to a third party, it has leaked.
And you should be aware that everything that goes into an AI can also come out. It might require a little coaxing to ‘spill the beans’, but it has been possible to extract models, training data and other users’ prompts. A researcher at Northwestern University tested more than 200 custom GPTs and managed to extract information from 97 % of these using only simple prompts. So it’s not just the AI operators that have insight into what you uploaded: adversaries can also extract training data from AI’s through prompt interaction.
This means that asking an AI to summarize a text with company secrets or sensitive personal information is not a good idea, even when reinforced learning is not enabled. Only feed the AI information that is not sensitive, such as commercial texts, website content, or publicly available information. Of course, a possible solution for this could be to run your own LLM in your private cloud or on-premise. While not impossible, the costs of this can be prohibitive on the short term.
Another way to address this is to instruct your custom LLM to warn the user if it detects sensitive information in the materials uploaded, and ignore that input.
Risk 2: Manipulating AI output
A second risk to AI is manipulation, for instance manipulation of chatbots or productivity enhancers such as Microsoft Copilot. AI’s can be coaxed into providing unwanted output, such as offensive language (turning your friendly customer service chatbot into a swearing pirate), or more serious attacks where other connected components can be targeted. If an AI is connected to the internet, it could even be manipulated into performing attacks on other systems. There are several ways of manipulating AI’s into performing unwanted or even malicious activities.
Most of these techniques use Prompt injection: Malicious inputs designed to manipulate an AI system's processing or output, tricking it into performing unintended actions or disclosing sensitive information. Most AI’s filter such prompts before passing them on to the actual LLM. However, clever ways of obfuscating, masking, splitting or encoding requests can be used to bypass these filters. A recent example of this was the research that used ASCII art to encode instruction and bypass filters: https://arxiv.org/abs/2402.11753.
Another way to manipulate AI’s is to use ‘virtualization’ or ‘role playing’ in which the attacker instructs the AI to take on a different personality or role, and simply pretend to be or do something. This can also bypass many filters.
It is still early days and we don’t yet know in detail what the consequences of this kind of manipulation could be. I can imagine that it could lead to new forms of extortion. Or maybe an attacker could manipulate a tool like CoPilot to generate vulnerable code that is then used in products. Or maybe the AI could be used to perform API calls or database lookups on other restricted services.
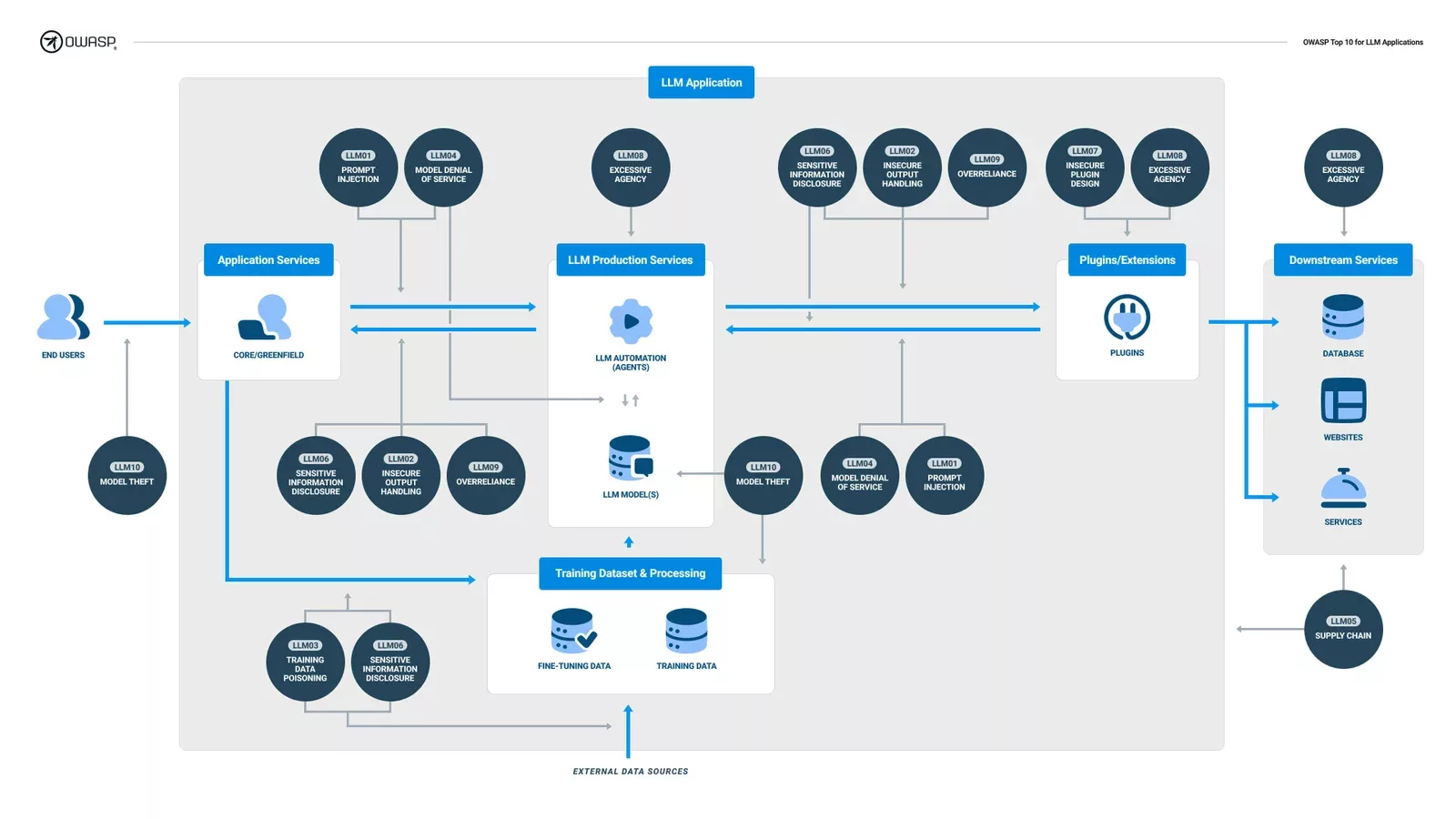
The OWASP Top 10 for LLM's. Source: LLMTop10.com
If you want to know more about these types of attack techniques, OWASP has a great resource at https://owaspai.org/ and of course there already is an OWASP Top10 for LLM’s: https://llmtop10.com/.
Securing the risks
So, how to control the risks when using AI’s? In terms of security controls, you should consider formulating an Acceptable Use Policy for AI’s. And you might also want to consider compiling an AI register of where AI’s are used in your organization and for what tasks. This will help to provide guidance to your coworkers and make them aware of the risks. Alternatively, it might be necessary to consider using on-premise AI’s, and luckily there are LLM’s and other models that allow that (although the computing resources required for this are often non-trivial). And of course: test, test, test.
Testing AI security
We receive quite a few questions from customers about AI security. Although it is relatively new for us (as it is for everyone), we are developing capabilities on this topic. We can perform basic AI security tests, where we can test the robustness and resilience of the LLM against attacks like model extraction, prompt injection, AI manipulation, model tainting, reuse or membership inference.
Finally, if you have questions about AI security, please contact your Account Manager or send an email to info@secura.com.
The cybersecurity world is changing. Subscribe to our Cyber Vision Newsletter on LinkedIn to learn more about the changing nature of cybersecurity, and the future of cyber resilience.
About the author
Ralph Moonen, Technical Director at Secura/Bureau Veritas
Ralph Moonen is Technical Director at Secura.
He is an information security specialist with 20+ yrs experience working with major (Fortune 500, governments, finance, international organisations etc.) clients in national and international settings.
Teacher at postgraduate IT-auditing course at Tilburg University.



Why choose Secura | Bureau Veritas
At Secura/Bureau Veritas, we are dedicated to being your trusted partner in cybersecurity. We go beyond quick fixes and isolated services. Our integrated approach makes sure that every aspect of your company or organization is cyber resilient, from your technology to your processes and your people.
Secura is the cybersecurity division of Bureau Veritas, specialized in testing, inspection and certification. Bureau Veritas was founded in 1828, has over 80.000 employees and is active in 140 countries.